Marco Marsala lanzó una candente pregunta en la comunidad ServerFault que pasará a las páginas de cientos de historias de terror que han enfrentado administradores de servidores: ¿Cómo me puedo recuperar de un rm -rf / ?
Actualización: Los moderadores de ServerFault limitaron el acceso a la publicación original, por lo que aquí les dejo una captura de pantalla en su lugar.
El diario The Independent amplió sobre la situación de Marsala y abordó la opinión de diferentes personas. Es una situación lamentable, pero me concentraré en hablar sobre cómo pudo evitar o recuperarse de esta desgracia en vez de un simple recuento de los daños.
El impacto
Una de las armas más poderosas de los administradores de sistemas en Linux, es la línea de comandos, así como el vasto número de programas y combinaciones que pueden lograrse con ellos.
El comando rm -rf es una instrucción simple, pero quizá la más temida. Básicamente instruye al sistema operativo a eliminar recursivamente (-r) y sin solicitar confirmación alguna (-f), todos los ficheros del sistema de archivos raiz ("/").
Para los usuarios de Windows que no están familiarizados con sistemas basados en Unix, esto es equivalente a un SHIFT+DEL sobre todas las carpetas en la unidad "C:" y hacer click en "Aceptar" para todos los diálogos de advertencia que se mostrarán.
El contexto
Marco es un administrador de servidores que brinda un servicio de alojamiento Web a cientos de clientes para publicar el sitio Web de éstos a través de Internet. Estos sitios o aplicaciones Web están usualmente conformados por ficheros y bases de datos.
Para brindar este servicio dispone de múltiples servidores Web en Linux, entre los cuales distribuye alrededor de 1535 sitios. Para agilizar la ejecución de tareas administrativas en estos servidores, usaba una herramienta llamada Ansible.
El escenario de Marco es similar al de miles de administradores que mantienen y soportan diversos servidores en Internet. Por esta razón, en adelante no me referiré directamente a Marco, sino que usaré el término "administrador" pues puede ser el caso de cualquiera.
Cómo pasó
El administrador creó algún tipo de script que tenía una instrucción "rm -rf", la cual tomaba como parámetro el valor de algunas variables para definir la ruta que se eliminaría. La idea era ejecutar este script en múltiples servidores en lote usando Ansible.
La desgracia ocurrió cuando el valor de estas variables no estaba definido correctamente y la instrucción de eliminación terminó siendo algo que el administrador jamás esperaba en su código de programación: rm -rfv /.
El respaldo
El crimen se consumó. Tras aceptar la realidad, la preocupación inmediata fue recuperar los datos. El administrador tenía almacenamientos de respaldo conectados a los servidores, pero al estar montados, también fueron víctimas de la eliminación.
La estrategia de respaldo del administrador hubiese sido efectiva para recuperarse de la situación pero no contaba con que serían eliminados también sólo por el hecho de estar conectados y montados dentro de la raíz del sistema de archivos.
Lecciones
A continuación una serie de lecciones aprendidas que podemos obtener de esta experiencia ajena para aplicar en nuestra estrategia de seguridad, prevención de desastres y recuperación.
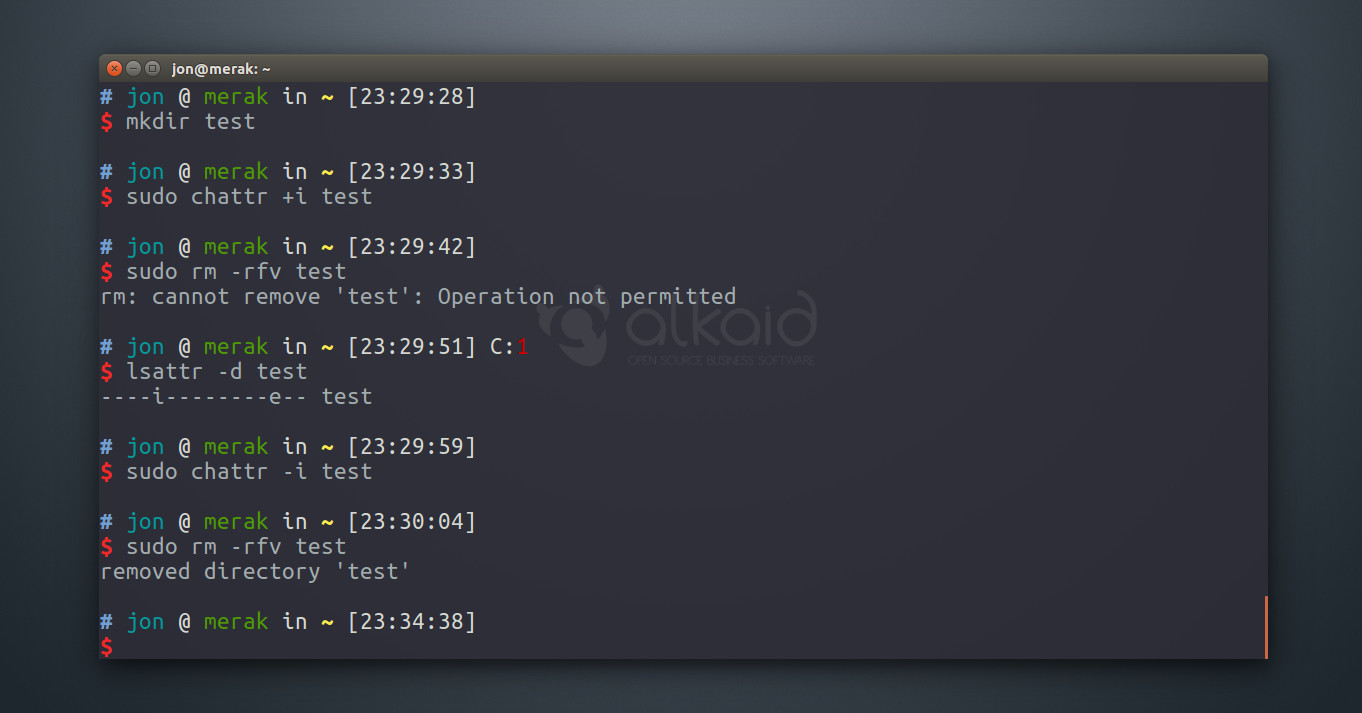
1. Atributos de Ficheros
La mayoría de sistemas de archivos en Linux disponen de una serie de atributos especiales que pueden asignarse tanto a folders como a carpetas específicas. He usado con éxito el atributo "Inmutable" para evitar que carpetas que albergan los sitios Web y bases de datos sean eliminadas por error. Para hacerlo de forma planificada, deben removerse estos atributos primero. Lea los páginas de manual de chattr y lsattr para sacar provecho a esta característica.
2. Privilegios de Usuario
Muchos procedimientos en Linux requieren ejecutarse en modo privilegiado, usualmente como usuario "root". Sin embargo, evítelo al máximo para reducir el riesgo, modelando esquemas de grupos, usuarios, permisos y elevación de privilegios apropiados. En servidores Web, he encontrado seguro y útil que cada sitio sea ejecutado con un usuario y grupo distinto al del servidor Web, al igual que la propiedad y permisos en sus ficheros.
3. Reglas de Protección
En Linux existen frameworks de seguridad que operan a nivel del sistema operativo y que le permiten definir una serie de reglas que protejan tanto la ejecución de instrucciones que pruedan comprometer la seguridad, así como la modificación o eliminación de ficheros y carpetas específicas. Los más conocidos son SELinux y AppArmor, écheles un vistazo y revise su soporte en la distribución que emplea.
4. Tenga más cuidado
El sistema no siempre podrá anticipar el error humano. Tome conciencia de las implicaciones al ejecutar comandos y lo que escribe o pega en la terminal, la ubicación donde los ejecuta, la extrapolación de variables y comodines. El comando "rm" posee una opción "--preserve-root" prevista para evitar la eliminación de la carpeta raíz ("/") y la opción "-i" para solicitar confirmación. Una alternativa útil puede ser un alias rm="rm --preserve-root -i" en su shell, pero el sano juicio siempre será su mayor escudo.
5. Respaldos
Deben haber respaldos, punto. Una decisión importante es la ubicación de éstos. Si valora sus datos, considere al menos un respaldo local en la misma ubicación del servidor y otro en una ubicación lejos de ser víctima del mismo daño. La frecuencia de respaldo puede cambiar entre uno y otro, pueden ser completos, incrementales o ambos. Además, puede que requiera un histórico de respaldos, en caso de que haya reaccionado tarde y el último respaldo sea una réplica del daño.
6. Contingencia
Si valora los datos pero también la capacidad de recuperar la operación tras un desastre, quizá debe considerar una arquitectura mínima de Replicación Máster-Esclavo, que de uno u otro modo le permita con mayor facilidad restaurar la disponibilidad del servicio y contar con redundancia de datos. En Linux existen varias soluciones comunes, desde respaldos incrementales con rsync hasta sincronizar en tiempo real bloques de almacenamiento usando DRBD.
7. Monitoreo y Pruebas
El mismo mecanismo de respaldo puede fallar y usted no darse cuenta. Por tanto, como otro servicio más, deberá procurar que esté operando como se espera. Puede que necesite monitorear, de uno u otro modo, la ejecución correcta del procedimiento de respaldo, la integridad de datos y el mismo proceso de recuperación para verificar que en caso de fallo la restauración será efectiva y la estrategia no fue en vano.
Tiene alguna otra sugerencia o aporte a la discusión? No dude en compartirla en los comentarios.