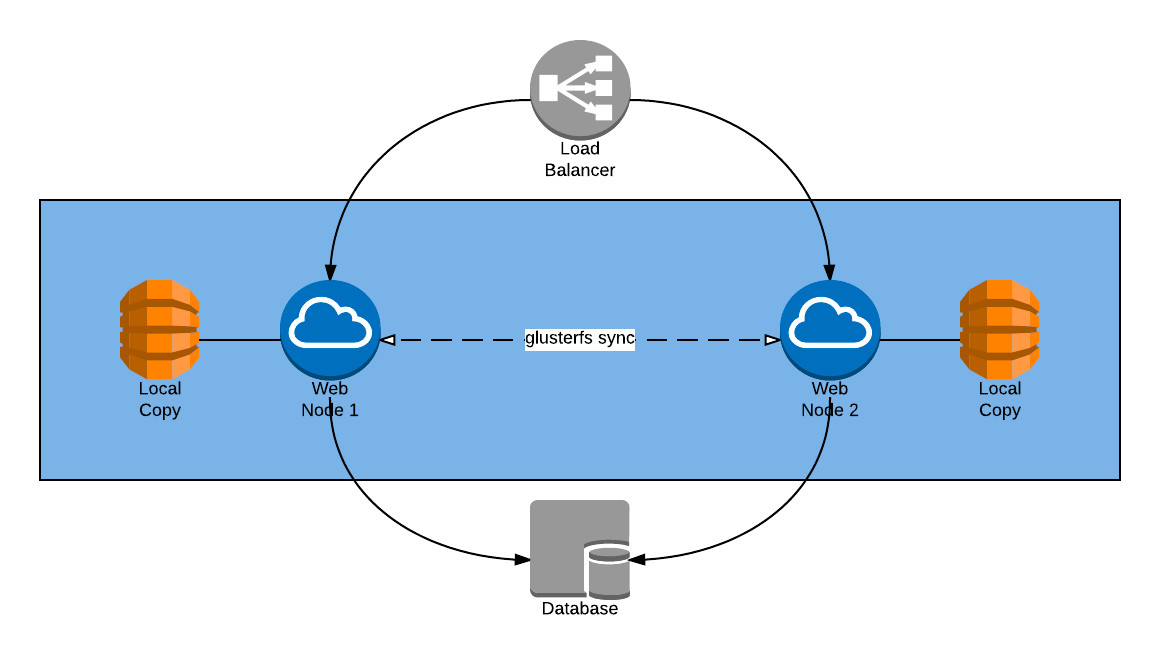
GlusterFS es un sistema de ficheros distribuido en red. La solución aquí descrita se enfoca en la replicación bi-direccional de un almacenamiento entre dos o más servidores Web que comparten una aplicación, procurando alta disponibilidad, recuperación automática y alto desempeño.
El problema
En nuestro caso, la aplicación es un sito construido en Wordpress, pero la técnica es aplicable a muchos otros escenarios. Wordpress está conformado por múltiples ficheros en PHP y de contenido estático, pero también permite a los administradores subir y actualizar ficheros a la aplicación.
Por otro lado, es frecuente actualizar Wordpress a su versión más reciente, proceso que lleva a cabo Wordpress por sí mismo sobrescribiendo los ficheros que conforman el núcleo de la aplicación. Además, en nuestro caso, se habilitó una caché de páginas cuyo contenido es escrito a disco.
Existe un Balanceador de Carga que distribuye las solicitudes a dos servidores Web que comparten exactamente los mismos ficheros de la aplicación, por lo que es importante que ambos conjuntos de ficheros estén en sincronía. La base de datos se encuentra en otro servidor aparte.
En caso de que uno de los servidores Web falle (desconexión de red o caída del servicio), el otro deberá asumir la carga. Cuando el otro servidor se recupere, ambos deben ver exactamente los mismos ficheros de la aplicación aún cuando ocurrieron cambios en ese lapso.
Antecedentes
Actualmente la solución está implementada con un servidor NFS aparte que comparte por red el almacenamiento de la aplicación con los dos servidores Web. Este servidor NFS es un clúster Pasivo-Activo con DRBD, por lo que facilita la alta disponibilidad del almacenamiento.
La debilidad de este mecanismo, es que la aplicación en Wordpress está conformada por más de 250 ficheros, que son accedidos por el servidor por cada solicitud que recibe la aplicación. La latencia de acceso a estos ficheros por NFS es alta, generando tiempos de respuesta de hasta 8 segundos.
Reducir considerablemente esta latencia no fue posible con optimizaciones a nivel de Caché Opcode y NFS, por lo que se prefirió usar un plugin de Caché de Página en Wordpress, reduciendo los accesos y el tiempo de respuesta a milisegundos. Sin embargo todo aquello que no pasa por caché, sigue siendo lento.
Por otro lado, el clúster de NFS requiere intervención manual para la recuperación de nodos fallidos cuando se presenta una situación de split-brain o se pierde la sincronización entre ambos dispositivos de almacenamiento. Si bien no afecta la disponibilidad del servicio, la intervención manual podría conducir a error humano.
En un momento anterior se optó por OCFS2, que básicamente consiste en compartir un mismo medio de almacenamiento físico en clúster, cumpliendo con las expectativas. Sin embargo las limitaciones de la plataforma de virtualización para exponer un mismo disco a dos máquinas virtuales activas desecharon esta opción.
La solución
Debido a que el mayor reto es mejorar el desempeño y que la latencia por accesos a decenas de ficheros en red por cada solicitud era un punto débil de la solución actual, se decidió buscar una alternativa que mantenga los ficheros de la aplicación localmente pero en sincronía entre los servidores Web.
Es importante considerar que el 95% o más de las solicitudes son lecturas de pequeños ficheros, no escrituras a disco, por lo que la sincronización de ficheros es casual y consume poco ancho de banda. Por otro lado, si bien la escalabilidad es importante, la capacidad actual en los dos servidores Web es más que suficiente.
Así, se analizaron distintas opciones, entre ellas una sincronización manual periódica con rsync o csync2, o bien con lsyncd. También fue considerado mantener el esquema actual con NFS pero usando una copia local del sistema de archivos para uso del servidor Web, manteniéndola sincronizada, usando lsyncd, contra el punto de montaje en NFS.
Aunque las opciones evaluadas no fueron ideas descabelladas, finalmente se eligió optar por GlusterFS en modalidad de replicación, por las siguientes razones que respondieron muy bien a las necesidades:
- Es un clúster Activo-Activo
- Cada servidor posee una copia
- Replicación bi-direccional inmediata
- Opera a nivel de ficheros, no bloques
- Chequeos de salud para aislar nodos
- Recuperación automática
- Simplificación de la arquitectura
- Disminución de uso de recursos
- No requiere almacenamiento compartido
- Sin intervención manual al recuperar
- Implementación es bastante fácil
- No requiere pila de software de clúster adicional
- Desempeño aceptable
- Disminución de latencia de red
Implementación
A continuación los pasos para implementar esta solución, descritos de forma general partiendo de que el administrador de sistemas sabe lo que hace o puede continuar investigando por su cuenta. Existen muchos ejemplos disponibles en la Web, pues en realidad es bastante fácil.
- Instalar GlusterFS en cada servidor Web
- Iniciar el servicio de GlusterFS en ambos servidores
- Agregar ambos servidores como peers mutuamente
- Crear un volumen gestionado por GlusterFS
- Montar el volumen en carpeta usada por servicio Web
- Copia los ficheros de la aplicación al punto de montaje
- Realizar múltiples pruebas de fallo y recuperación
- Someter a prueba el desempeño de la solución
- Reducir tiempo de desconexión a 10 segundos
- Configurar GlusterFS para iniciar al arranque
- Configurar /etc/fstab con punto de montaje permanente
Conclusión
GlusterFS es una excelente solución escalable para un Clúster de Alta Disponibilidad entre servidores Web que requieren compartir el mismo almacenamiento con sincronización, mientras se mejora el rendimiento al acceder a disco. Las pruebas se realizaron hasta con hasta 4 servidores Web en clúster, pero el número puede aumentar.