
Conforme la demanda y criticidad de una aplicación Web crece, ésta requerirá de mecanismos de redundancia de datos y más recursos de procesamiento que asuman la carga de trabajo, sin descuidar la mayor disponibilidad del servicio.
Con el surgimiento de servicios de infraestructura en la nube como Google Compute, Amazon AWS y Rackspace Cloud, la demanda es un poco más fácil de gestionar, pues es ofrecida como un servicio más del ofrecimiento de los proveedores. Sin embargo, quienes mantienen aplicaciones en centros de datos con una infraestructura privada, suelen requerir implementar por su cuenta los mecanismos que resuelvan estas necesidades.
Esta publicación aborda un caso de uso particular, que servirá como referencia para futuras arquitecturas similares. Cada aplicación requerirá un análisis distinto, aunque existan patrones comunes que pueden facilitar su diseño.
Problema
Nuestro escenario presenta el caso de una aplicación Web hipotética que opera en una infraestructura privada, puede ser un Portal o una Tienda en línea, por citar dos ejemplos concretos. Esta aplicación es servida a través de un único servidor que emplea Apache HTTPd y PHP como entorno de ejecución.
La aplicación hace uso de una base de datos en un único servidor MariaDB para alojar datos relacionales, mientras que mantiene una carpeta en el servidor Web con contenido variable y no estructurado, por ejemplo imágenes y otros documentos que suelen ser subidos a través de la aplicación.
Durante los últimos meses, la demanda del servicio ha crecido y los recursos de hardware asignados al servidor Web se están volviendo insuficientes para cubrir la necesidad, el servidor opera con largos tiempos de respuesta y en ocasiones ha fallado a causa de esta razón.
Si hay un fallo en el servidor Web o en el servidor de Base de Datos, toda la aplicación deja de operar, lo cual impacta gravemente al negocio. Por otro lado, la información almacenada en el motor de base de datos se ha vuelto crítica por lo que debe haber redundancia.
El reto, es modelar una arquitectura que haga frente a la carga de trabajo y sea escalable, procurando que la disponibilidad del servicio sea la mayor posible. El modelo puede ser tolerante a fallos pero permitir su rápida recuperación evitando la pérdida de datos al máximo.
Concepto
Resolver el problema implica rediseñar la arquitectura actual y tanto modelos como herramientas altamente probadas para entornos en producción. La respuesta usual suele ser la implementación de un modelo de Alta Disponibilidad para cada uno de los roles que conforman la arquitectura.
Implementar Alta Disponibilidad requiere configurar clústers para los roles, con distintos modelos de operación y recursos de acuerdo a cada caso. No voy a extender en el tema, por lo que refiérase a la siguiente documentación para comprender cómo funciona Alta Disponibilidad en Linux.
Advierto que no es un tema sencillo. Si no está familiarizado con el tema, deberá hacerlo y le tomará tiempo, e incluso quizá consultar documentación adicional. Es todo un reto con resultados muy positivos.
- High Availability Cluster
- Load Balancing
- Linux HA
- Single Point of Failure
- Linux Virtual Server
- ClusterLabs
- Clustered File System
- Distributed Block Device
- SBD Fencing
- STONITH
Propuesta
Una vez entendidos los principios y conceptos implicados, preste atención al siguiente diagrama de arquitectura propuesto para resolver en la medida de lo posible el problema en cuestión. Cada caja en el diagrama encierra un rol en la arquitectura, y para cada uno de ellos hay un clúster de Alta Disponibilidad configurado.
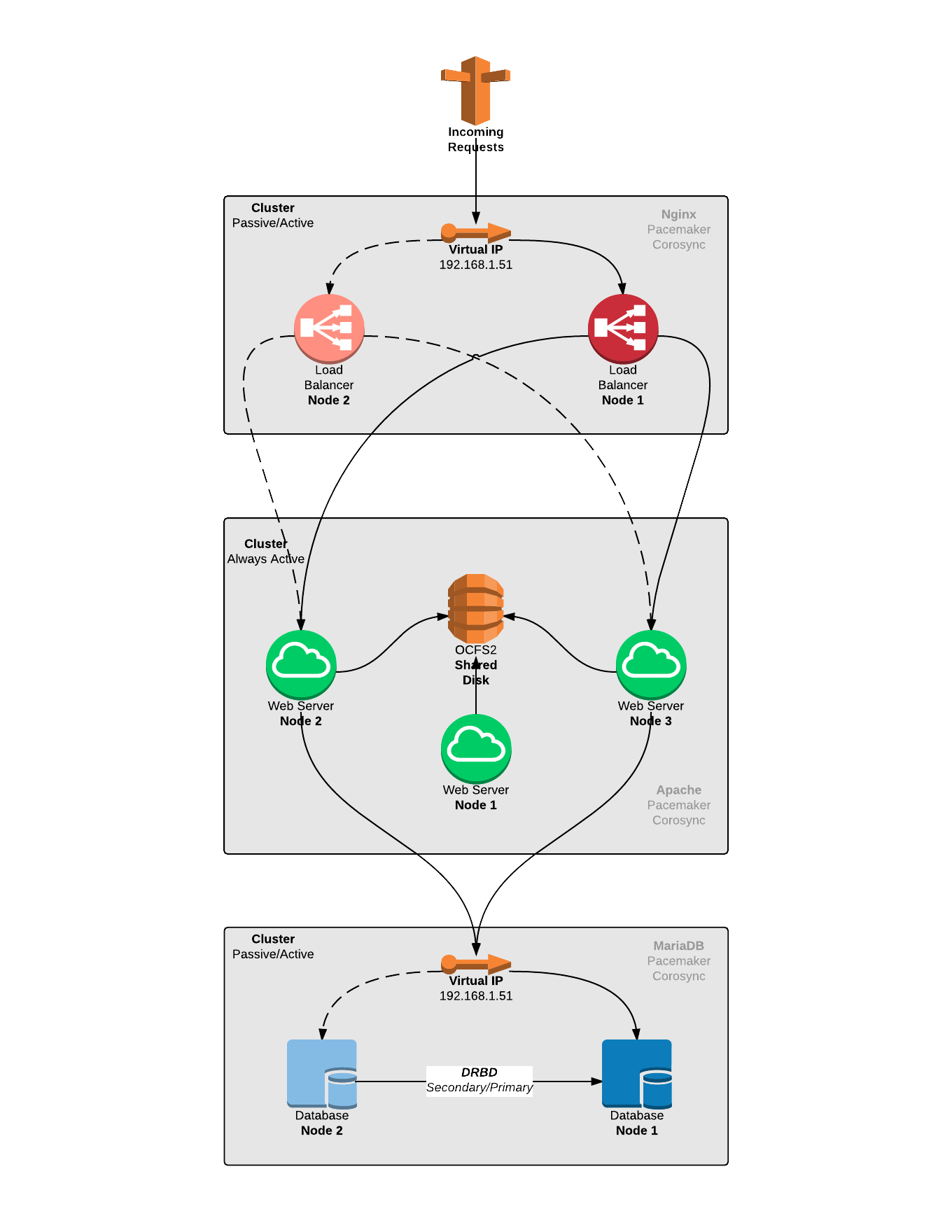
En el diagrama usted puede apreciar tres grandes roles en la arquitectura, descritos cada uno a continuación:
Balanceador
Conocidos en inglés como "Load Balancer", es un servicio que recibe las solicitudes de una aplicación y las distribuye entre uno o más servidores Web. Este servicio será quien ponga la cara por la aplicación hacia el exterior. Hay muchas implementaciones usando Nginx, HA Proxy, Varnish, Squid, Apache HTTPd, entre otros. En nuestro caso, preferiremos Nginx.
Los servidores Web disponibles, también conocidos desde la perspectiva de un Balanceador de Carga como "upstream servers", son registrados ante el Balanceador para que éste les asigne cargas de trabajo. Cuando un "upstream server" falle, el Balanceador podrá excluirlo (banned) por un tiempo hasta que se recupere.
El clúster de balanceo está formado por dos nodos. Solamente uno de estos nodos estará activo y tendrá asignada la IP virtual por la cual recibirá solicitudes. En caso de fallo del nodo activo, el otro nodo podrá asumir su lugar asumiendo por su cuenta la IP virtual de forma automática.
Servidor Web
Es el servicio que recibe y realiza el procesamiento completo de una solicitud Web. En el caso de la aplicación que nos compete, el servidor empleado es Apache HTTPd. Requeriremos varias instancias de servidor Web en máquinas distintas para soportar la carga de trabajo que enviará el Balanceador.
Como todos los nodos en este clúster deben servir la misma aplicación, requerirán acceder a los mismos ficheros que componente la aplicación y su configuración, para que el procesamiento sea transparente. Para ello utilizarán un almacenamiento disponible a través de un disco de bloques compartido por hardware. Esto requerirá un Clustered File System.
El cúster de servidores Web estará conformado por al menos tres servidores, todos ellos activos. En caso de requerir más nodos, deberá añadirlos en números impares para evitar una condición de split-brain que comprometa el clúster. El acceso al almacenamiento es controlado por un servicio de bloqueo llamado DLM y el sistema de archivos OCFS2.
Base de Datos
El servicio de base de datos estará disponible a todos los servidores Web, de modo que todos observen exactamente los mismos datos relacionales de la aplicación cuando procesen solicitudes HTTP. Los motores de base de datos suelen estar previstos gestionar la concurrencia de acceso por parte de múltiples aplicaciones.
En nuestro caso estamos empleando MariaDB como motor de base de datos, que provee un rendimiento aceptable para la mayoría de portales y tiendas de comercio electrónico. El servidor de base de datos cuenta con los recursos necesarios para servir de forma óptima las consultas de los servidores Web.
El clúster de base de datos estará conformado por dos nodos. Solamente uno de estos nodos estará activo y tendrá asignada la IP virtual por la cual recibirá solicitudes, así como sincronizará los datos al nodo pasivo mediante DRBD. En caso de fallo del nodo activo, el otro nodo podrá asumir su lugar de forma automática reasignándose la IP virtual, pero requerirá intervención manual para reactivar la sincronización.
Tecnología
A continuación mencionamos la pila de software usada para soportar este modelo:
- Corosync: Plataforma de comunicación del Clúster
- Pacemaker: Gestor de Recursos del Clúster (CRM)
- OCFS2: Sistema de Archivos para Clúster (disco compartido)
- DRBD: Espejo de Dispositivos de Bloque (Network/Software RAID-1)
- Linux Virtual Server: IP Virtuales en Linux
- Linux Watchdog: Temporizador en caso de fallo
- SBD Fencing: Mecanismo alterno para Fencing mediante disco
- Split-Brain: División del clúster en dos cabezas independientes
- SLES 11 SP3: Sistema Operativo con paquetería de Alta Disponibilidad
Consideraciones
- El modelo de Alta Disponibilidad siempre debe procurar la reducción de puntos únicos de fallo, conocidos en inglés com SPoF (Single Point of Failure). Por tanto, incluso los canales de comunicación por red deberían ser redundantes.
- Debe considerar en todo momento un mecanismo de aislamiento (fencing) en caso de que algún nodo deba ser excluido inmediatamente del clúster por alguna condición de fallo, como medida de protección del resto del sistema.
- En un clúster de nodos activos, como es el caso del rol de Servidor Web, es sumamente importante evitar al máximo la condición de split-brain. Considere siempre asignar una cantidad de nodos impar para conformar quórum en situaciones de fallo.
- El Balanceador de Carga no suele requerir acceso a datos compartidos, aunque bajo una condición en la que los nodos "upstream servers" se añadan dinámicamente, pueda ser requerido reajustar su configuración para contemplarlos.
- Dado que los ficheros y el contenido no estructurado de la aplicación se almacenan en un mismo almacenamiento, deberá tomar las previsiones de redundancia de estos datos también.
- Si no desea o no puede usar OCFS2 para que varios nodos en clúster accedan a un mismo disco duro, puede emplear NFS o algún otro sistema de archivos en red, siempre que no supongan alguna limitación o riesgo para la aplicación y su disponibilidad.
- La replicación de datos en MariaBD a través de DRBD, debe ser realizada manualmente ante una situación de fallo, en caso de que no sea posible determinar automáticamente quién posee los datos más confiables para la aplicación.
- Como alternativa a un clúster de Alta Disponibilidad para MariaDB, puede considerar tecnología alternativa como Galera Cluster, entre otros. Hay mucha información documentada sobre clusters en MySQL/MariaDB.
- El sistema operativo sugerido para este esquema es SUSE Linux Enterprise Linux 11 SP3. Cuenta con paquetería especializada y soportada a largo término en la pila de tecnológica descrita, a un costo razonable. Consulte también el soporte de otras distribuciones.
- En caso de haber una condición de fallo de alguno de los nodos en el clúster, es necesaria la implementación de mecanismos de aislamiento ("fencing") para evitar la propagación de errores en el sistema por parte de nodos fallidos.
- Incorpore los elementos de esta infrastructura a un servicio de monitoreo que le facilite identificar de forma temprana o inmediata la ocurrencia de fallos.
Conclusión
Incorporar un modelo de Clúster en Alta Disponibilidad para una aplicación requiere mucho análisis, previsión de condiciones de error y procedimientos de recuperación. La pérdida de datos, no disponibilidad o fallo de los sistemas suele costar muchísimo dinero para muchas empresas, por lo cual la inversión en estos modelos suele ser totalmente justificada.
Los sistemas Linux cuentan con pilas de software muy bien documentadas para la configuración de este tipo de entornos. Por la variedad de herramientas de software requeridas para la configuración de un Clúster de Alta Disponibilidad, suele ser preferible optar por distribuciones que posean ya paquetes integrados que faciliten la actualización, integración, configuración y mantenimiento de este tipo de sistemas a largo plazo.
Esta publicación describió un caso particular, que podría ser o no similar al suyo, así como tres modelos distintos de configuración de clúster que podrían servir como referencia para futuros diseños. No obstante, cada aplicación tendrá sus particularidades, por lo cual es obligatorio estudiar cada escenario con tal de asegurar la mayor disponibilidad y el menor riesgo para sus sistemas.
No dude en consultar a expertos que han enfrentado diseñado distintos modelos de Clúster en Alta Disponibilidad con Linux, para que le brinden la asesoría necesaria en la implementación. Un sistema de alta disponibilidad mal diseñado, podría tener un impacto muy grave en su infraestructura y negocio.
